Introduzione
Strumenti e dati “giusti” consentono di ottenere risultati sorprendenti, e soprattutto allargano la platea di chi può fare analisi e ricerca su certe informazioni.
In questo post sarà illustrato come un piccolo file di 500 kB, possa essere il punto di ingresso sui dati aperti del Piano Nazionale di Ripresa e Resilienza (PNRR).
Si tratta di un file, di un database DuckDB, che “contiene” l’elenco delle principali tabelle del Catalogo Open Data di Italiadomani, il portale del Governo che ospita i dati del PNRR.
La parola “contiene” è tra virgolette perché il file non contiene realmente i dati, ma semplicemente delle viste, dei puntatori ai dati veri e propri. Ma per le modalità in cui è stato costruito, è possibile fare query e analisi senza quasi accorgersi di questo.
In questo modo è possibile allargare il numero di persone che possono elaborare questi dati, ma c’è un prerequisito: conoscere il linguaggio SQL.
Il SQL è un linguaggio di programmazione che consente di interrogare le tabelle di un database.
Come interrogare il database
Il file in formato DuckDB si può scaricare da qui. È leggibile con decine di software, per tutti i sistemi operativi.
Uno degli strumenti che si possono utilizzare è DBeaver, un client SQL open source per tutte le principali piattaforme, che consente di interrogare database di diversi tipi, tra cui DuckDB.
Una volta installato e lanciato, si potrà scegliere a che tipo di database connettersi: in questo caso DuckDB (vedi Figura 1).
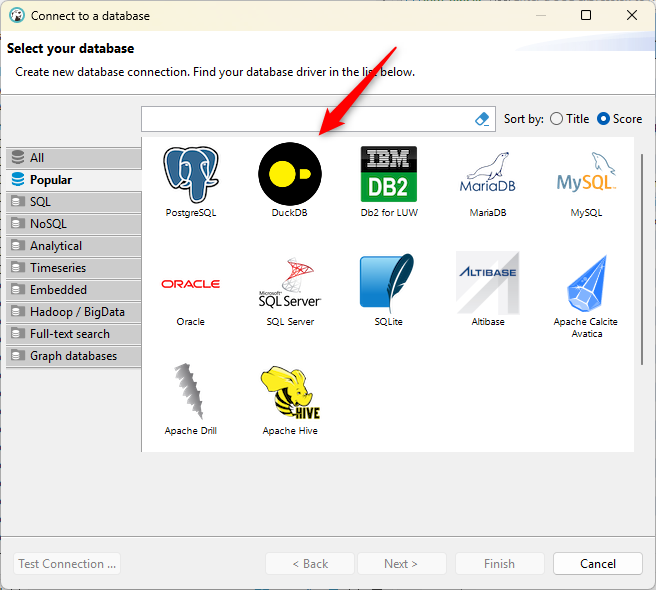
Nei passaggi successivi della configurazione si dovrà indicare a quale file DuckDB connettersi. Qui sarà il file pnrr.db scaricato in precedenza.
Una volta connessi, il database sarà visibile sulla sinistra, nel navigatore dei database. E facendo clic sui vari segni >, sarà possibile vedere le 1️⃣ tabelle e le 2️⃣ viste, ecc. in cui è strutturato (vedi Figura 2).
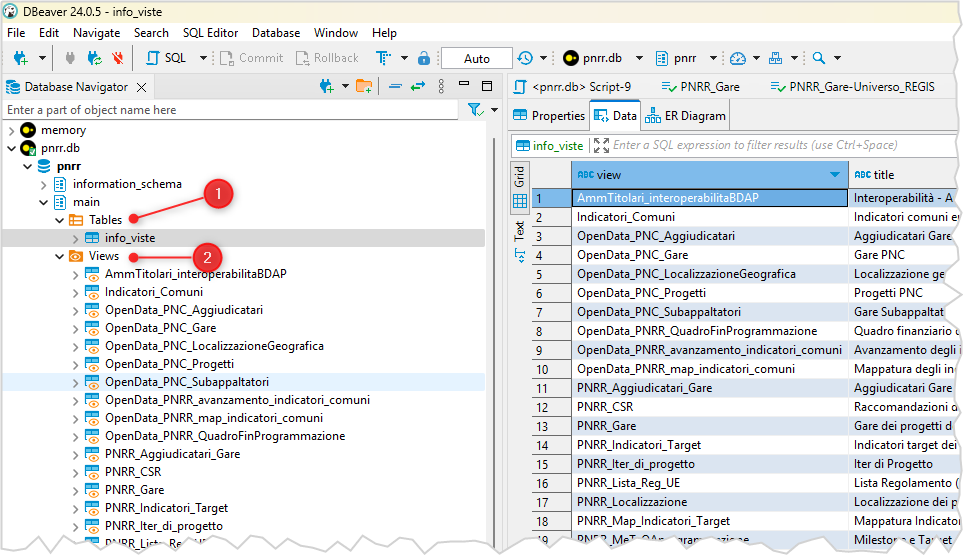
La tabella è soltanto una, si chiama info_viste e contiene l’elenco di tutte le viste presenti nel database. In questa tabella, per ogni vista:
- il nome della vista;
- il titolo del dataset;
- l’URL della pagina del dataset;
- il file che ha fatto da sorgente;
- la descrizione del dataset;
- la data di osservazione dei dati che hanno fatto da sorgente.
Questa tabella è quindi una tabella di metadati. Mentre per accedere ai dati bisogna utilizzare una o più delle viste presenti.
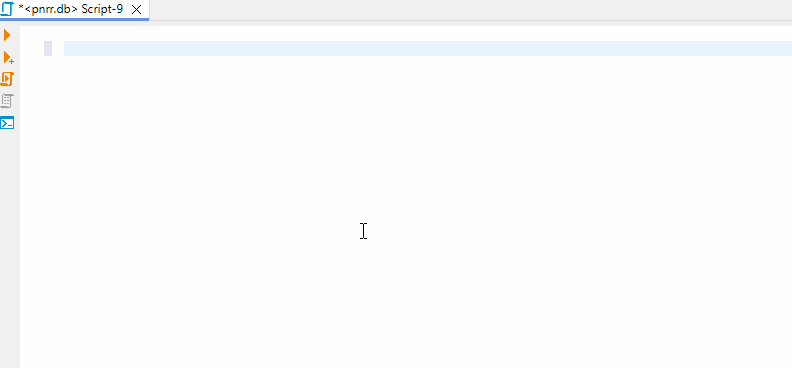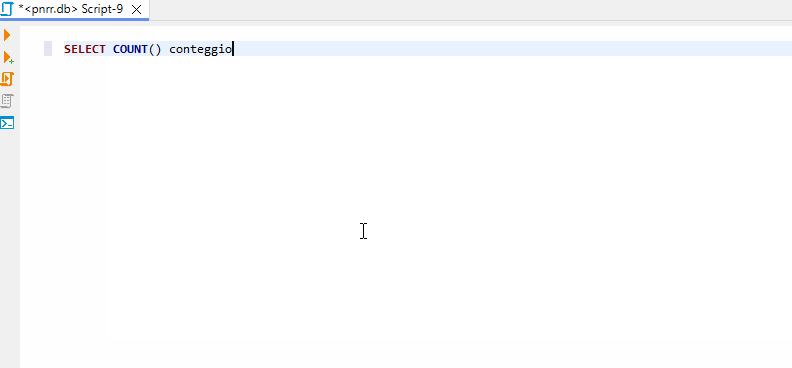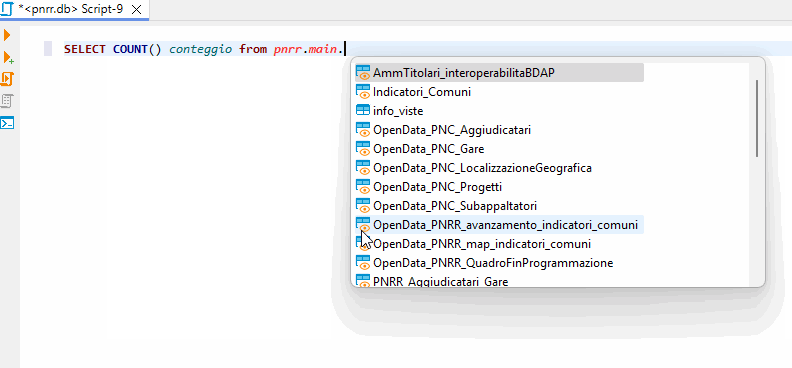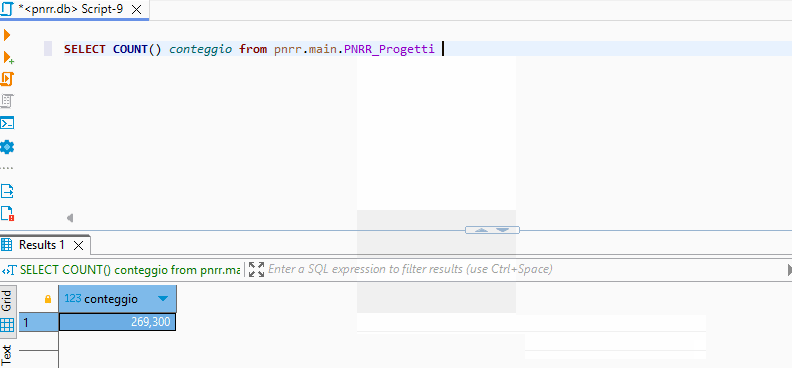
E una prima query potrebbe essere quella per conteggiare il numero di progetti del PNRR:
SELECT COUNT() conteggio from pnrr.main.PNRR_Progetti;Sono, al momento, 269.300 progetti. La cosa interessante è che il risultato è molto rapido, nonostante il db non contenga i dati, ma solo dei puntatori.
Ed è molto comodo, che strumenti come DBeaver abbiano l’auto-completamento delle query, come è possibile vedere in Figura 3.
Il PNRR è suddiviso in Missioni e la query per conteggiare il numero di progetti per Missione - che viene eseguita in 0.5 secondi, è:
SELECT
"Descrizione Missione",
COUNT() conteggio
FROM
pnrr.main.PNRR_Progetti
GROUP BY
ALL
ORDER BY
conteggio DESC;| Descrizione Missione | conteggio |
|---|---|
| Digitalizzazione, innovazione, competitività e cultura | 83661 |
| Rivoluzione verde e transizione ecologica | 81486 |
| Istruzione e ricerca | 75677 |
| Inclusione e coesione | 18088 |
| Salute | 10084 |
| Infrastrutture per una mobilità sostenibile | 285 |
| REPowerEU | 19 |
Ma per dare un’idea più efficace della comodità, di poter utilizzare un piccolo file da 500 kB, si può costruire una query più complessa che mette in relazione due viste, ovvero due dataset: quello dei Progetti e quello delle Localizzazioni.
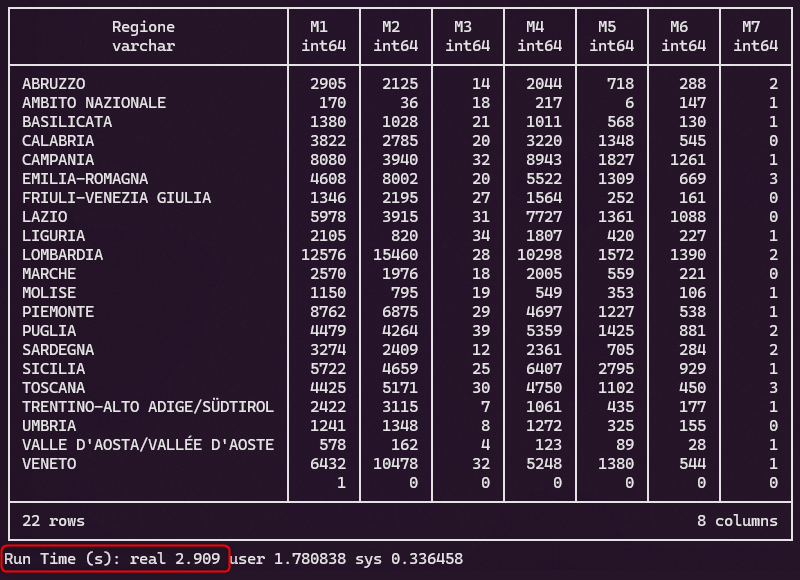
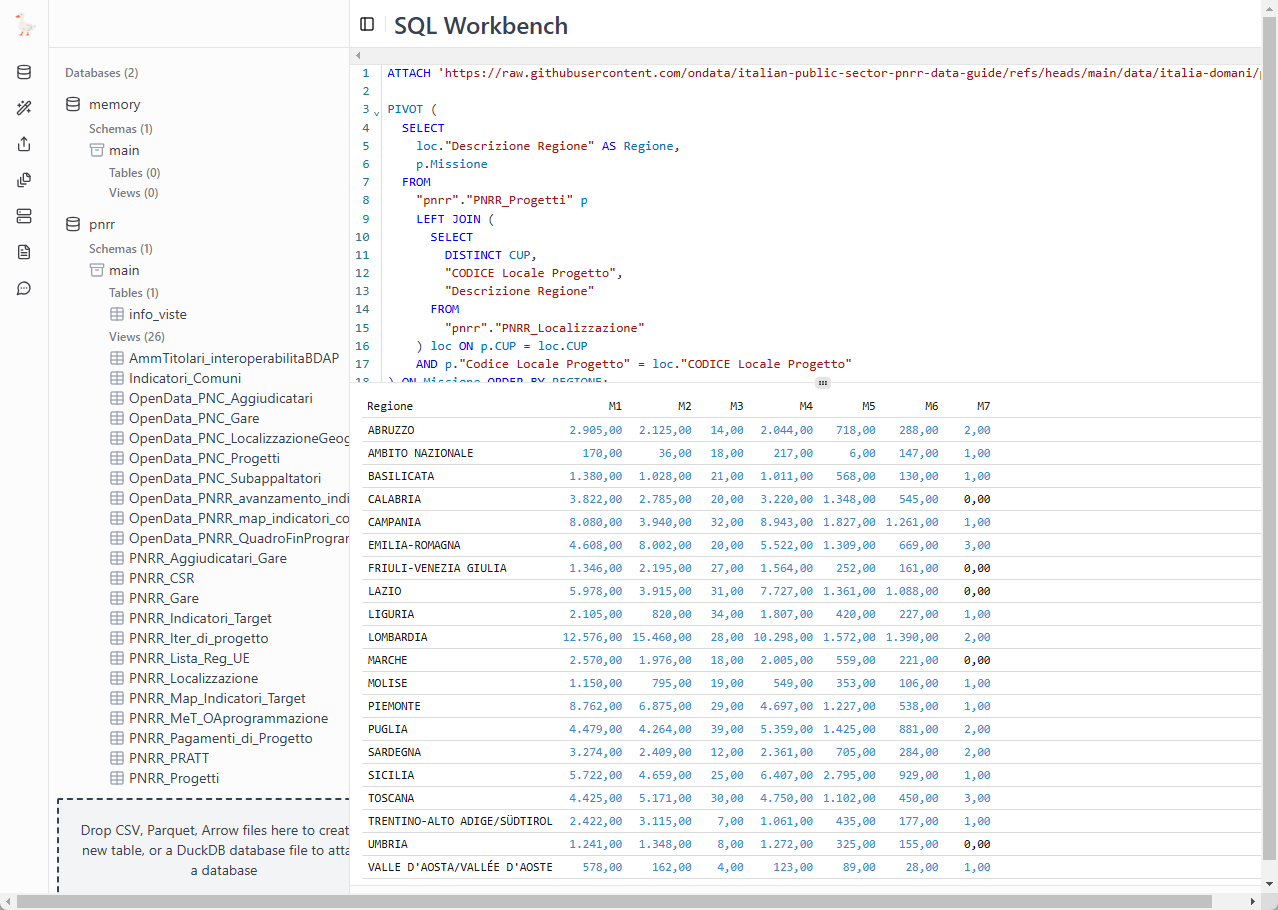
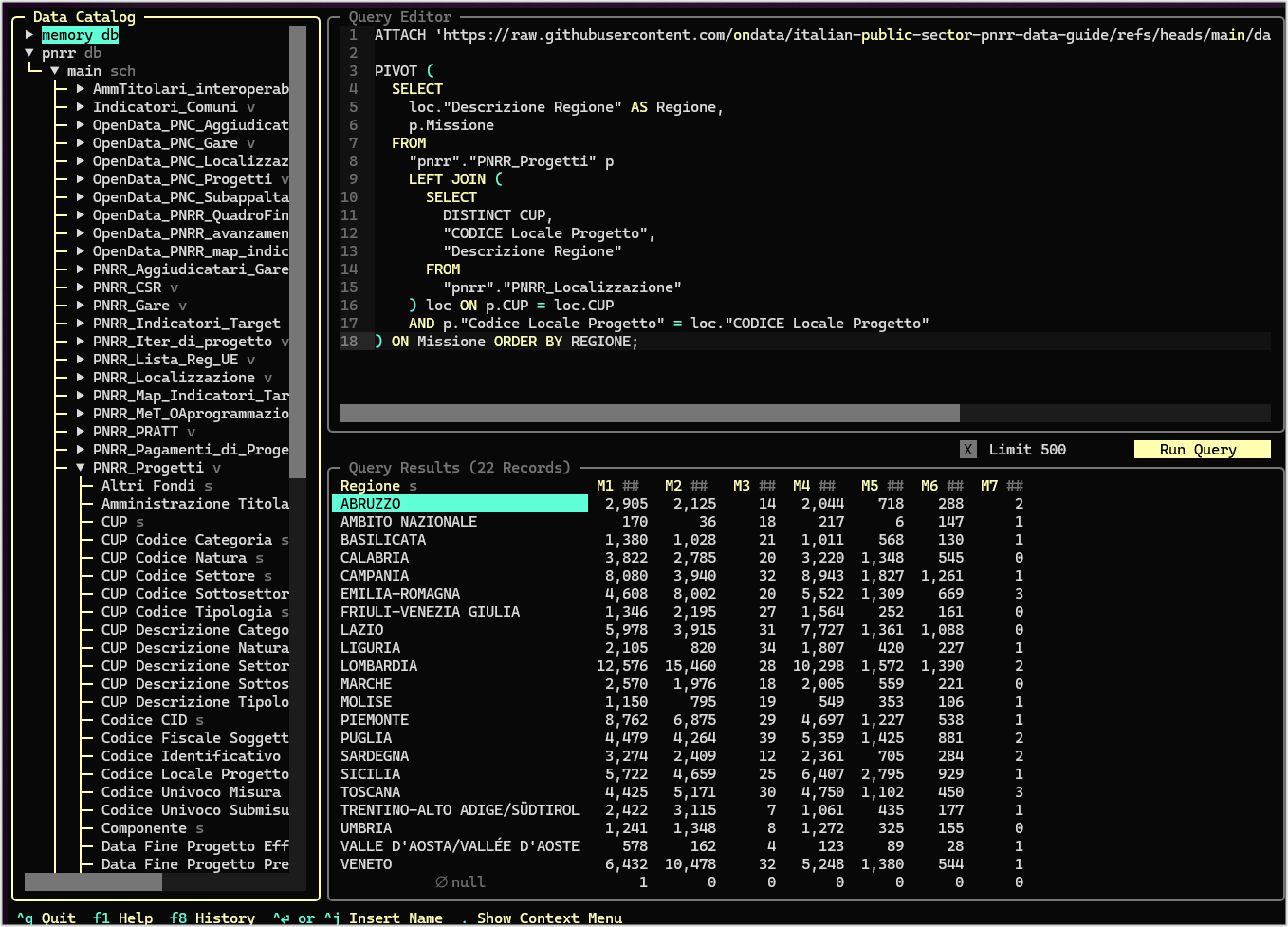
L’obiettivo è quello di creare una tabella di sintesi, una tabella pivot, per restituisca il numero di progetti per Missione per ogni Regione.
La query è
PIVOT (
SELECT
loc."Descrizione Regione" AS Regione,
p.Missione
FROM
"pnrr"."PNRR_Progetti" p
LEFT JOIN (
SELECT
DISTINCT CUP,
"CODICE Locale Progetto",
"Descrizione Regione"
FROM
"pnrr"."PNRR_Localizzazione"
) loc ON p.CUP = loc.CUP
AND p."Codice Locale Progetto" = loc."CODICE Locale Progetto"
) ON MissioneE in pochi secondi viene restituito il risultato (vedi Figura 4).
Come è stato creato il database
L’ispirazione per la creazione di questa modalità di accesso ai dati del PNRR, viene dalla lettura di questo ottimo articolo, in cui si spiega come DuckDB possa diventare un catalogo portatile per la gestione dei dati, da fonti diverse (file parquet da fonti Amazon S3, database PostgreSQL, tabelle su Google Cloud, ecc.).
Per questo file è stata replicata la logica descritta nell’articolo, ma sono state necessarie delle pre-lavorazioni dei dati.
Sul sito Italiadomani i file sono disponibili in formato CSV (JSON e XLSX) e una query SQL tramite DuckDB si può fare puntando direttamente all’URL del file. Per sapere ad esempio quanti sono i progetti del PNRR la query sarebbe:
SELECT COUNT(*) FROM read_csv_auto('https://www.italiadomani.gov.it/content/dam/sogei-ng/opendata/PNRR_Progetti.csv')Questo è possibile grazie all’estensione httpfs di DuckDB, che consente di leggere file da URL HTTP o da Amazon S3. Ci sono però dei problemi:
- a volte il server di Italiadomani non risponde in modo adeguato, e la query fallisce;
- il formato
CSVnon è ottimizzato per query su file “grandi”, che non risiedano sul proprio PC, perché è necessario scaricare tutto il file per fare la query.
Entrambi i punti sono abbastanza bloccanti e, per superarli, sono state fatte due cose:
- pubblicare i file con i dati in uno spazio web che rispondesse meglio alle chiamate
HTTP; - convertire i file
CSVin un formato più adatto per fare query su file “grandi” remoti, come il formatoparquet.
Lo spazio web creato, che ospita i file è GitHub, e la cartella è questa:
https://github.com/ondata/italian-public-sector-pnrr-data-guide/tree/main/data/italia-domani/parquet
L’URL di accesso diretto ai file ha questa struttura:
https://raw.githubusercontent.com/ondata/italian-public-sector-pnrr-data-guide/refs/heads/main/data/italia-domani/parquet/Nome_File.parquet
Quindi ad esempio l’URL del dataset dei progetti è:
https://raw.githubusercontent.com/ondata/italian-public-sector-pnrr-data-guide/refs/heads/main/data/italia-domani/parquet/PNRR_Progetti.parquet
E la query per conteggiare i progetti è quindi:
SELECT COUNT(*) AS numero_progetti
FROM
'https://raw.githubusercontent.com/ondata/italian-public-sector-pnrr-data-guide/refs/heads/main/data/italia-domani/parquet/PNRR_Progetti.parquet';Il database DuckDB è stato implementato creando una vista per ogni file parquet presente nella suddetta cartella:
CREATE
OR replace view "PNRR_Progetti" AS
SELECT
*
FROM
read_parquet(
'https://raw.githubusercontent.com/ondata/italian-public-sector-pnrr-data-guide/refs/heads/main/data/italia-domani/parquet/PNRR_Progetti.parquet'
);Due esempi di accesso “live”
Un database così strutturato, dà la possibilità di abilitare l’accesso ai dati in modo “live”, ovvero senza dover scaricare il file e interrogarlo in locale.
Due applicazioni web, che consentono di accedere a risorse remote e interrogarle, lanciando una versione di DuckDB nel browser, senza dovere installare nulla sono queste due:
- la DuckDB Shell;
- il SQL Workbench.
In entrambi i casi basta prima dare il comando di ATTACH per collegare il database DuckDB remoto, e poi fare tutte le query che si vogliono.
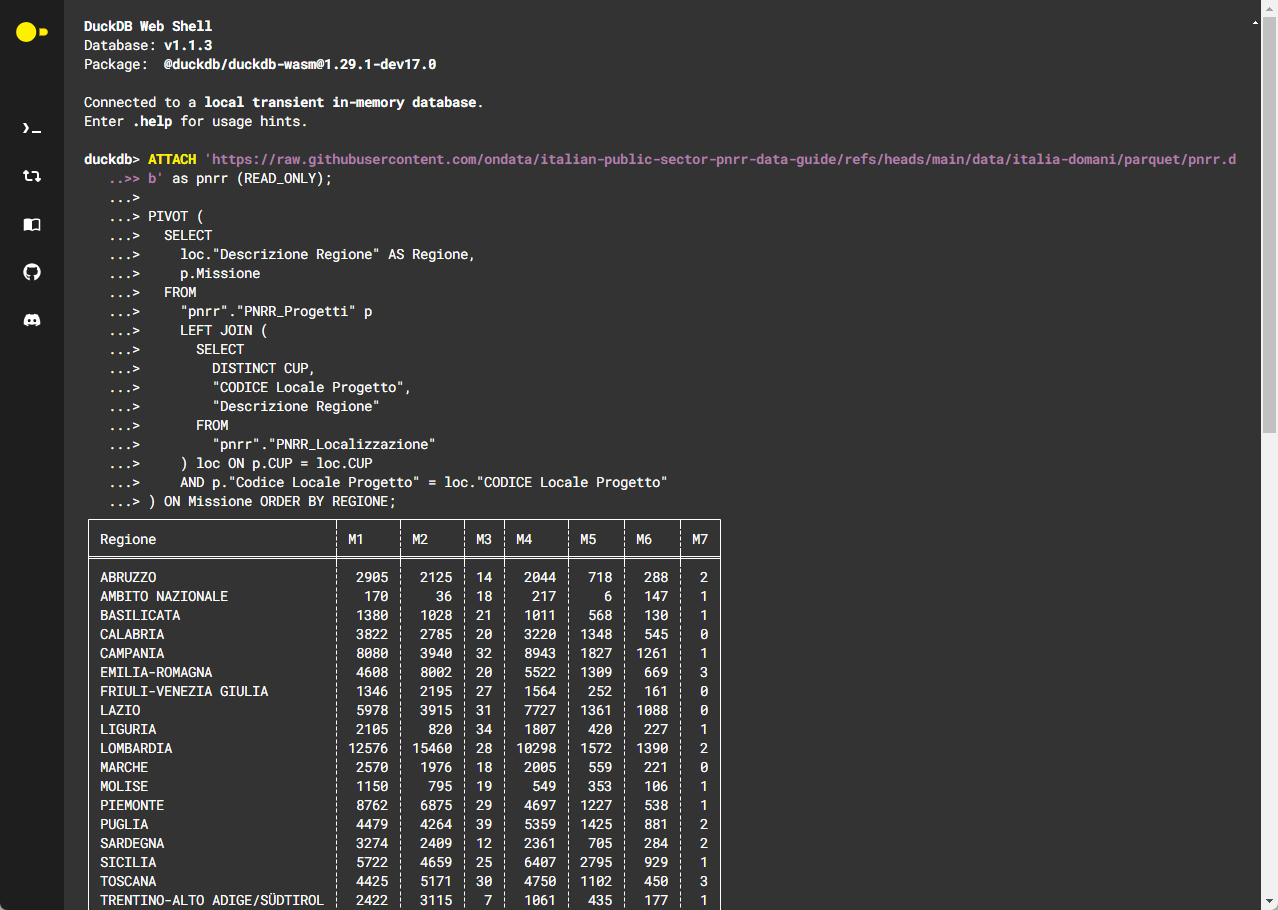
Ad esempio, per la tabella pivot vista sopra, basterà per entrambi i casi:
ATTACH 'https://raw.githubusercontent.com/ondata/italian-public-sector-pnrr-data-guide/refs/heads/main/data/italia-domani/parquet/pnrr.db' as pnrr (READ_ONLY);
PIVOT (
SELECT
loc."Descrizione Regione" AS Regione,
p.Missione
FROM
"pnrr"."PNRR_Progetti" p
LEFT JOIN (
SELECT
DISTINCT CUP,
"CODICE Locale Progetto",
"Descrizione Regione"
FROM
"pnrr"."PNRR_Localizzazione"
) loc ON p.CUP = loc.CUP
AND p."Codice Locale Progetto" = loc."CODICE Locale Progetto"
) ON Missione ORDER BY REGIONE;Ed è interessante il fatto che le query costruite in questo modo, possano essere condivise con altre persone con un link, come questi due (sotto le immagini con l’anteprima dei risultati):
Lo strumento consigliato
Una cosa comodissima di questa modalità di accesso ai dati PNRR, è che è possibile leggerli nel modo preferito: con un client SQL come DBeaver da installare sulla propria macchina, con un client web come DuckDB Shell o SQL Workbench, con un linguaggio di programmazione come Python o R, ecc. e anche da riga di comando.
Per chi è abituato a lavorare da riga di comando, un ottimo strumento è il sorprendente e comodissimo Harlequin, gratuito e open source, installabile su qualsiasi sistema operativo, e in grado di accedere a decine di database, tra cui DuckDB.
Note conclusive
In questo post si vuole sottolineare la comodità di accedere a una banca dati, a partire da un file piccolo e senza rinunciare alla possibilità di costruire analisi complesse e ricche.
Non è la modalità facile e unica con cui capire tutto sui numeri del PNRR, ma si ha la possibilità di fare un primo passo, e di farlo in modo molto più semplice di quanto si possa pensare.
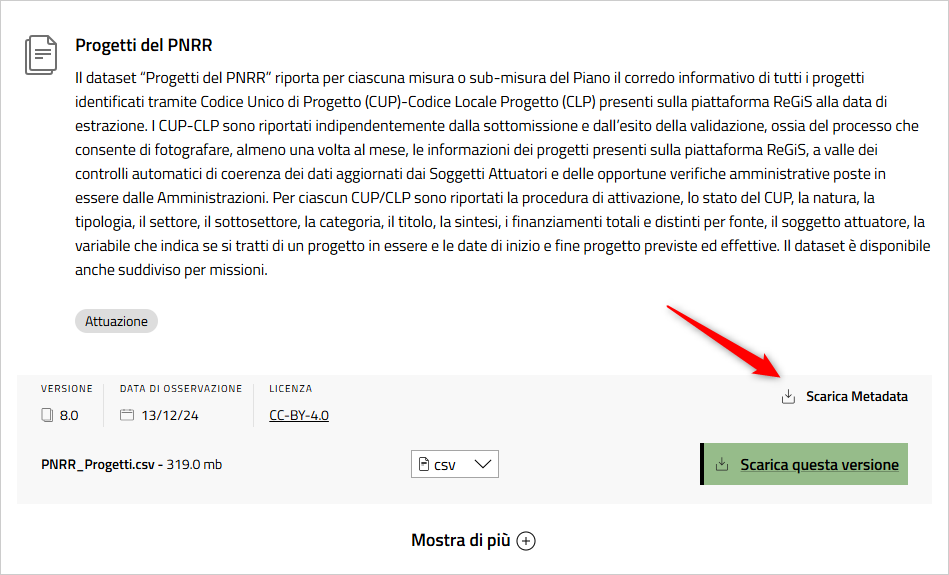
Ci sono alcuni requisiti propedeutici: approfondire come è strutturato il PNRR, leggere i metadati delle tabelle (in ogni pagina dei dati, c’è un link ai metadati, vedi Figura 8), e conoscere il linguaggio SQL.
Questo è un primo rilascio del database, per mostrare un caso d’uso “tecnico”. Al momento non è una risorsa su cui è pianificato un aggiornamento automatico e non è stato fatto alcun controllo di qualità.
In prospettiva è probabile che verrà creata una procedura automatica per aggiornare il database, e verrà migliorata la qualità dei dati con verifiche sulla coerenza dello schema dati.
I file sorgente, pubblicati su Italiadomani hanno alcuni problemi, di facile risoluzione, a da conoscere:
- l’encoding dei file
CSV. È nella gran parte dei casiUTF-8, ma in alcuni casi non è così e bisogna fare attenzione per l’accesso e l’eventuale conversione; - l’importante file
CSVsui “Soggetti dei progetti del PNRR” - che fra l’altro è uno di quelli di dimensioni maggiori - contiene diverse righe non corrette, con un numero di colonne non compatibile con lo schema.
Riprendo infine una riflessione già fatta nell’apprezzato post “Gestire file CSV grandi, brutti e cattivi”: con uno sforzo piccolo e un po’ di cura, è possibile pubblicare dati in modalità che ampliano di molto il numero di persone che possono accedervi e utilizzarli in modo efficace.
Ad esempio:
- questi file potrebbero pure essere pubblicati su un bucket di Amazon S3 (o altre modalità simili), e DuckDB (o altri client) potrebbe leggerli da lì, con grande rapidità;
- si potrebbero pubblicare anche in formato compresso, ad esempio in
csv.gz, o ancora meglio in formati efficienti e specializzati per l’analisi, come ilparquet; - si potrebbe pubblicare anche un unico file in formato DuckDB, con tutte le tabelle del PNRR, con la corretta definizione dei tipi di campo, con definite le chiavi primarie, le chiavi esterne, ecc..