Questo post ci ha consentito di fare una prima lettura di questa importante banca dati e sono emerse alcune criticità. Una è quelle citata nel post, sulle righe con numero di colonne errato.
Quella che ci sembra più importante è relativa alla natura dei progetti, che era la novità più importante: sul CSV ci sono soltanto 3 tipologie, quindi nulla è cambiato. Le altre tipologie al momento sono visibili soltanto sul front-end del sito.
È stato annunciato, anche dopo una nostra segnalazione, che i dati saranno aggiornati in tal senso entro la fine di febbraio 2024.
Da pochissimo, dal 14 febbraio 2024, è andato online il nuovo portale OpenCUP.
OpenCUP mette a disposizione di tutti - cittadini, istituzioni ed altri enti - i dati, in formato aperto, sulle decisioni di investimento pubblico finanziate con fondi pubblici nazionali, comunitarie o regionali o con risorse private registrate con il Codice Unico di Progetto.
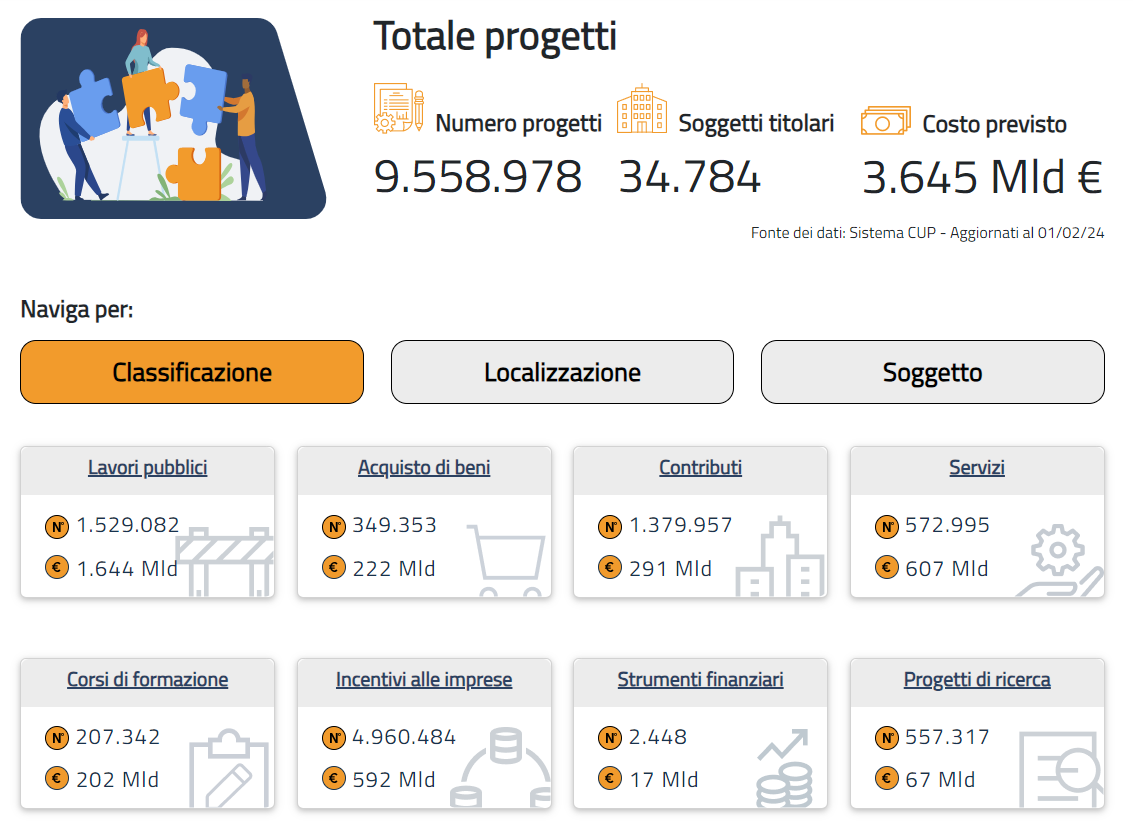
La novità più importante di questo aggiornamento, è legata alla natura degli interventi in elenco: a “Lavori Pubblici” e “Incentivi alle imprese e Contributi per calamità naturali”, si aggiungono “acquisti di beni, servizi, corsi di formazione, strumenti finanziari, progetti di ricerca e contributi a entità diverse dalle unità produttive per una Pubblica Amministrazione più trasparente e vicina al cittadino” (qui la notizia di lancio).
In numeri si passa da circa 6,5 a 9,5 milioni di progetti.
Gli Open Data di OpenCUP
Sul sito di OpenCUP, è disponibile da tempo la sezione OpenData. Con questo aggiornamento, sono stati pubblicati i nuovi dati, in formato CSV e XML.
Bisogna scorrere la pagina e guardare la sezione “Progetti OpenData”.
In questo post, mostreremo rapidamente come esplorare il file “Complessivo” di tutti i progetti.
È un file “grande”. Quello in formato CSV è compresso come zip: pesa circa 2.9 GB, e decompresso 23 GB. È probabilmente il file CSV più grande (o uno dei più grandi), pubblicato in una sezione open data di un sito di una Pubblica Amministrazione italiana.
Non è gestibile con un comune foglio di calcolo, né con tanti altri strumenti.
A riga di comando invece si può osservare, filtrare, e analizzare, con grande leggerezza e rapidità.
Ci sono alcune righe con un numero di separatori di campo errato: devono essere 90. Per estrarre soltanto quelle con 90 separatori si può usare awk:
unzip -p "OpenData Complessivo.zip" | awk '{if(gsub(/\|/,"&") == 90) print}' >open_cup_corrette.csvVedi anche la sezione Importazione dell’intero file.
La prima lettura
Un file così grande richiede un po’ di tempo per il download e poi per la decompressione.
Per fortuna però è possibile fare una prima lettura immediata, dopo il download, senza decomprimere per intero il file.
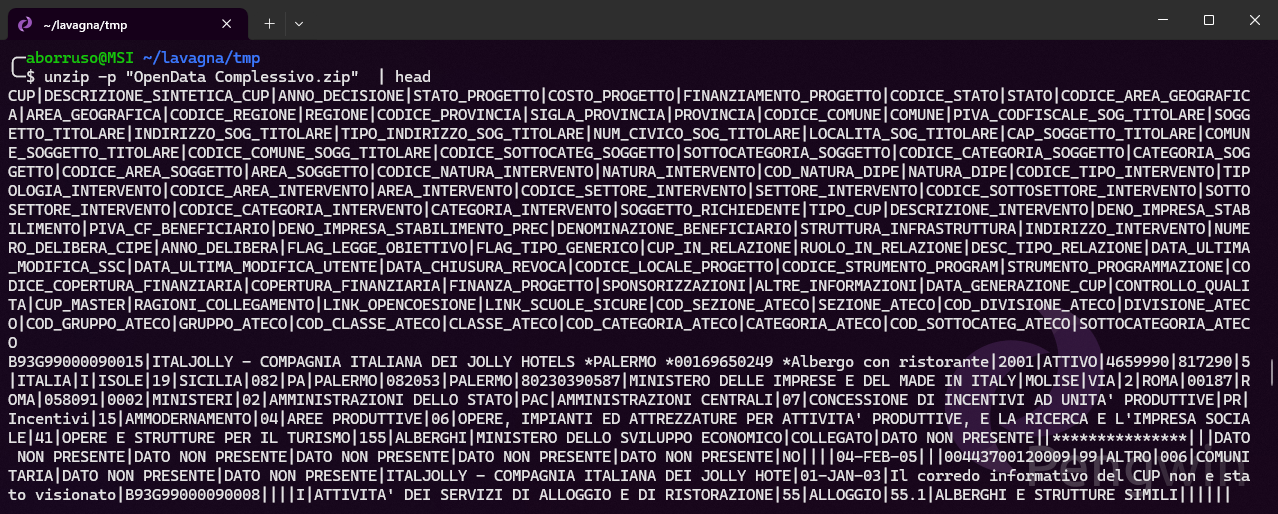
Si può usare l’utilty unzip e lanciare il comando unzip -p nomefile.zip. Ma per una prima esplorazione, l’ideale è leggere soltanto le prime righe. E per fortuna esiste il comando head, che fa proprio questo e di default legge le prime 10 righe.:
unzip -p "OpenData Complessivo.zip" | headE subito si vedrà qualcosa come in Figura 2, che ci restituisce già elementi interessanti:
- i nomi dei campi;
- il separatore è il
|
Estrazione di un campione
Viste le prime 10 righe e mappate le caratteristiche del CSV, il passo consigliato successivo è quello dell’estrazione di un campione di righe più ampio, per fare un’analisi più approfondita.
Con una piccola modifica al comando soprastante, si possono ad esempio estrarre le prime 10.000 righe e salvarle in un nuovo file CSV (in 0.055 secondi):
unzip -p "OpenData Complessivo.zip" | head -n 10000 > campione.csvE questo nuovo file sarà esplorabile con foglio elettronico o con altri strumenti. A me ad esempio piace usare VisiData per queste cose, con cui di solito subito osservo un po’ di dati sui campi (i valori nulli, i valori distinti, ecc.).
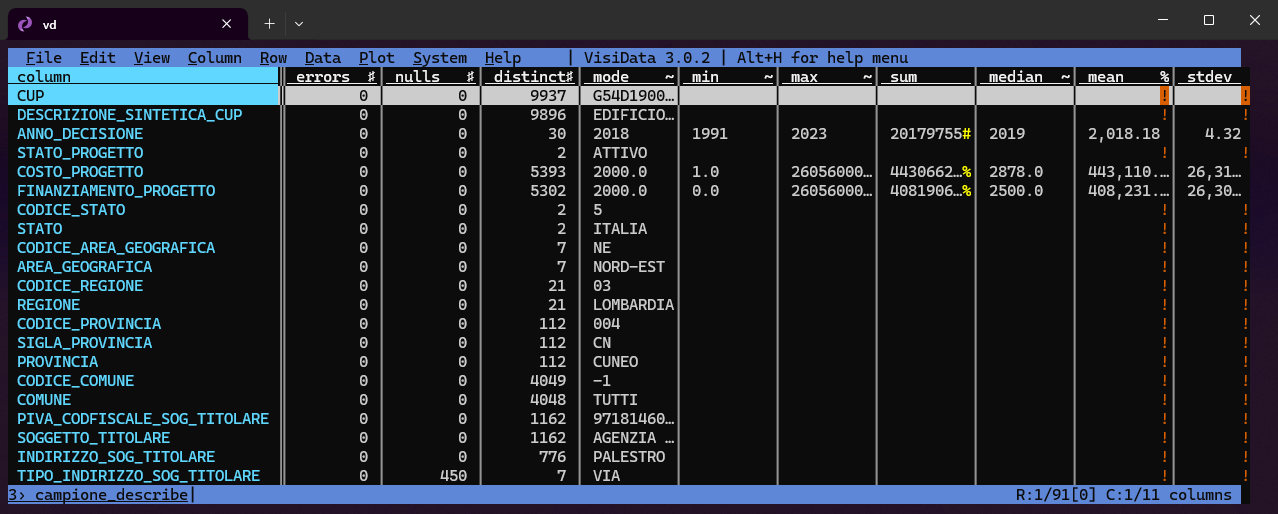
Il professore Taibi ci ha fatto notare che questo non è un vero campione, ma soltanto le prime n righe del file. Un vero campione dovrebbe essere estratto in modo casuale, ma sarebbe necessario decomprimere tutto il file per farlo. E quindi qui, per un’esplorazione rapida, ci accontentiamo di questo.
Filtrare l’intero file
L’esplorazione del campione consente di farsi un’idea di quali sono quei campi/colonne che fanno un po’ da elementi “categorici”, da usare come filtro per estrarre solo le righe che ci interessano.
Tra questi ad esempio il campo SOGGETTO_TITOLARE, con il nome della Pubblica Amministrazione, titolare del progetto, che posso usare per estrarre ad esempio tutti i progetti in cui la PA titolare è “REGIONE AUTONOMA DELLA SICILIA”.
L’utility grep - una delle più importanti di tutti i tempi - è perfetta per questo scopo.
unzip -p "OpenData Complessivo.zip" | grep -P '\|REGIONE AUTONOMA DELLA SICILIA\|' >regione_siciliana.csvSi applica un filtro al file CSV zippato di input, e per ogni riga in cui è presente la stringa REGIONE AUTONOMA DELLA SICILIA tra due caratteri |, viene salvata nel file regione_siciliana.csv. Nel filtro è stato inserito il carattere \ prima del |, perché | è un carattere speciale.
E in un minuto e mezzo circa, sul mio buon (ma normale) PC ottengo 392.395 progetti associati alla Regione Siciliana, dopo aver letto 9,5 milioni di righe.
Ma così c’è un problema: si perde l’intestazione del file, si perdono i nomi delle colonne. C’è allora da modificare il filtro ed estrarre anche la prima riga. E tutto questo è facile, grazie all’esplorazione fatta, in cui ho visto che la prima riga contiene ad esempio la stringa “ANNO_DECISIONE”.
Il nuovo comando sarà:
unzip -p "OpenData Complessivo.zip" | \
grep -P '(ANNO_DECISIONE|\|REGIONE AUTONOMA DELLA SICILIA\|)' >regione_siciliana.csvCosì vengono cercate tutte le righe che contengono o ANNO_DECISIONE o |REGIONE AUTONOMA DELLA SICILIA| e quindi viene restituito un CSV con i nomi delle colonne e le righe filtrate.
Un file parquet a partire dai dati filtrati
Questo ultimo passo, perché è utile avere a disposizione questi dati anche in un formato più efficiente, come il parquet, che è un formato di file binario, compresso e colonnare, che permette di ridurre notevolmente lo spazio occupato e di velocizzare le operazioni di lettura e analisi.
Per chi non ne ha mai sentito parlare, ne ho scritto lungamente qui.
L’utility stavolta è DuckDB. E il comando è:
unzip -p "OpenData Complessivo.zip" | \
grep -P '(ANNO_DECISIONE|\|REGIONE AUTONOMA DELLA SICILIA\|)' | \
duckdb -c "COPY(
SELECT * FROM read_csv_auto('/dev/stdin', delim = '|')
) TO 'regione_siciliana.parquet' (
FORMAT 'parquet',
COMPRESSION 'ZSTD',
ROW_GROUP_SIZE 100000
)"Alcune note su questo comando (messo su più righe, per migliorare la leggibilità):
- si parte dal comando precedente, con il filtro per estrarre il campione;
- si passa l’output a
duckdb, che legge ilCSVdastdine nelSELECTal posto del nome del file è necessario inserire'/dev/stdin', che è il file virtuale che rappresenta lo standard input; - si usa il comando
COPYper copiare questa selezione in un fileparquetchiamatoregione_siciliana.parquet, con compressioneZSTDe con unROW_GROUP_SIZEdi100000.
Tutto circa sempre in un minuto e mezzo, con un file di output che pesa circa 33 MB, contro i 530 MB del file CSV.
Importazione dell’intero file
Il file CSV completo ha, alla data di oggi (15 Febbraio 2024) un problema a 2 righe (su 17.065.848), che hanno un numero errato di colonne (91 anziché 90). Per poterlo importare occorre filtrare solo le linee che hanno un numero di colonne corretto.
È possibile importare il file in un DB in formato DuckDB con i seguenti comandi (occorre avere il file CSV su disco per limitare l’occupazione di RAM):
unzip "OpenData Complessivo.zip"
awk -F\| '{if (NF-1 == 90) { print } }' < TOTALE.csv > TOTALEfix.csv
duckdb OpenCUP.db -c "CREATE TABLE OpenCUP AS SELECT * FROM read_csv_auto('TOTALEfix.csv',delim='|',header = true,dateformat='%d-%b-%y',parallel=FALSE,types={'DATA_ULTIMA_MODIFICA_SSC':'DATE','DATA_ULTIMA_MODIFICA_UTENTE':'DATE','DATA_CHIUSURA_REVOCA':'DATE','DATA_GENERAZIONE_CUP':'DATE'});"Notare che è stato esplicitato il formato delle date, e quali sono i campi di tipo DATE, in modo che DuckDB converta correttamente i campi relativi, che sono del tipo 01-JAN-15. Questo permette sia una migliore gestione dei dati, che una rappresentazione più efficiente in termini di spazio su disco.
Il file DuckDB risultante, a fronte di un CSV di 23.946.237.777 byte, è 4.431.294.464 byte, con una riduzione a circa 1/6, merito del formato binario contro quello ASCII.
Prestazioni del formato DuckDB
Una query di esempio
time duckdb OpenCUP.db -c "SELECT ANNO_DECISIONE, COUNT(*) FROM OpenCUP GROUP BY ANNO_DECISIONE" > /dev/null
real 0m0,039s
user 0m0,156s
sys 0m0,063sConversione nel formato Parquet
Con il comando
duckdb OpenCUP.db -c "COPY (SELECT * FROM OpenCUP) TO 'OpenCUP.parquet' (FORMAT 'PARQUET', CODEC 'ZSTD');si ottiene un file Parquet di 2.296.193.848 byte, con una riduzione di circa 1/2 rispetto al formato nativo DuckDB.
Se con questo comando si hanno problemi di memoria si può provare a impostare SET preserve_insertion_order=false:
duckdb OpenCUP.db -c "SET preserve_insertion_order=false;COPY (SELECT * FROM OpenCUP) TO 'OpenCUP.parquet' (FORMAT 'PARQUET', CODEC 'ZSTD');"Le prestazioni del formato Parquet sono notevoli
time duckdb -s 'SELECT ANNO_DECISIONE, COUNT (*) FROM read_parquet("OpenCUP.parquet") GROUP BY ANNO_DECISIONE;' > /dev/null
real 0m0,074s
user 0m0,372s
sys 0m0,043sNote sui tempi di esecuzione
I tempi di esecuzione sono stati misurati su un computer abbastanza “normale”, con 16 GB di RAM e questo processore:
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i7-1280P
CPU family: 6
Model: 154
Thread(s) per core: 2
Core(s) per socket: 10Questa la tabella riassuntiva dei tempi di esecuzione:
| Operazione | Tempo (minuti:secondi) |
|---|---|
Download (con wget) |
12:13.81 |
Decompressione (con unzip) |
1:33.05 |
Estrazione delle sole righe corrette (con ugrep)1 |
2:25.63 |
| Importazione in DuckDB | 4:15.97 |
| Conversione in Parquet | 0:28.811 |
Versione più sintetica e rapida
In DuckDB, nell’import dei file CSV, c’è l’opzione ignore_errors=true, che permette di ignorare le righe che contengono errori (come quelle con un numero di colonne errato). E quindi si può saltare la creazione di un secondo grande CSV per applicare il filtro.
Inoltre, se non abbiamo bisogno del database DuckDB, possiamo convertire direttamente il file CSV in parquet e saltare quindi un altro passaggio.
Il comando sintetico è:
duckdb -c "SET preserve_insertion_order=false;COPY(SELECT * FROM read_csv_auto('TOTALE.csv',delim='|',header = true,ignore_errors=true,dateformat='%d-%b-%y',parallel=FALSE,types={'DATA_ULTIMA_MODIFICA_SSC':'DATE','DATA_ULTIMA_MODIFICA_UTENTE':'DATE','DATA_CHIUSURA_REVOCA':'DATE','DATA_GENERAZIONE_CUP':'DATE'})) TO 'opencup.parquet' WITH (FORMAT PARQUET, COMPRESSION ZSTD,ROW_GROUP_SIZE 100000)"Così facendo, c’è un risparmio di tempo di circa il 30%.
Note finali
Questa descritta è soltanto una modalità per fare soprattutto una prima esplorazione e analisi di questo nuovo e importante aggiornamento dei dati di OpenCUP.
È utilissima per capire per cosa è possibile usare questi dati, quali sono le informazioni che ci interessano di più, che storia poter raccontare, che mappa creare, che dashboard realizzare, come usare l’intelligenza artificiale per arricchirli, come metterli in relazione con altri dati, ecc..
Ma sono dati grandi, e in produzione bisognerà andare un po’ oltre l’utilizzo delle eccezionali utility a riga di comando. In ogni caso DuckDB, se usato bene, fa già tanta tanta roba (partizionando il dataset originario in più file parquet, si ha disposizione tutto il dataset con una grandissima facilità di accesso e lettura).
Note
ugrep '^(?:[^|]*\|){90}[^|]*$' TOTALE.csv >TOTALEfix.csv↩︎